


หนึ่งในงานที่เราชาว Developer แทบทุกคนต้องเคยเจอในชีวิตการทำงานก็คือการหาวิธีดึงข้อมูลจากเว็บคนอื่นเค้า ฮ่า ๆ เหตุผลหลัก ๆ เลยก็เพราะบางครั้ง ข้อมูลที่พวกเราอยากได้ในเว็บนั้นมันไม่มี Public API ให้เราดึงข้อมูลมาได้ด้วยท่าที่ง่าย ๆ
นึกภาพแบบโจทย์จริงที่อาจจะเจอ เช่น เราอยากดึงข้อมูลรอบหนังของโรงหนังมาแสดงในระบบของเรา ทีนี้จะทำยังไงล่ะครับ เพราะ เค้าก็ไม่ได้มีการปล่อย Public API ออกมาซ่ะด้วย
ดังนั้นมันจึงมีวิธีการได้มาซึ่งข้อมูลที่สายเทาค่อนข้างไปทางดำ ๆ นั่นก็คือ เทคนิค ที่มีชื่อว่าการทำ Web scraping การทำแบบนี้ก็ค่อนข้างเสี่ยงที่เราจะถูกแบน IP เพราะ มันเสมือนการคุกคามเว็บไซต์คนอื่นเค้า รวมทั้งเสมือนกับการคัดลอกข้อมูลมาโดยไม่ได้รับอนุญาติจากเจ้าของข้อมูล ถ้าหากต้องการข้อมูลจากเว็บไซต์ไหนแบบจริงจังนั้น ผมแนะนำว่าให้ลองติดต่อขอข้อมูลอย่างถูกต้องดีกว่าครับผม
วันนี้เราจะมาทดลองดึงข้อมูลกันครับ และ ก่อนที่เราจะเริ่มใช้งานเครื่องมือนี้ ผมจะพาพวกเราทุกคนไปทำความรู้จักหลักการของการทำ Web scraping กันครับ
Concept ของการทำ Web scraping
เครื่องมือในการทำ Web scraping นั้นมีหลายตัว ขึ้นอยู่กับภาษาเลยครับ แต่วันนี้เราจะมาลองเล่นเครื่องมือในภาษา Node.js กันครับ โดยเครื่องมือนี้มีชื่อว่า Osmosis ครับ โดยทั่วไปการทำ Web scraping นั้นเราต้องมาทำความเข้าใจโครงสร้างของ HTML เบื้องต้นก่อนครับ
ปกติการเข้าเว็บไซต์ซักหนึ่งเว็บสิ่งที่เกิดขึ้นเป็นดังภาพนี้คือ
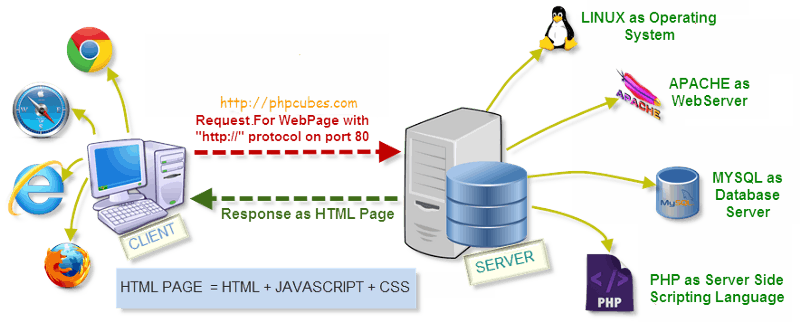
https://people.rit.edu/~agy5732/140/proj2/http
- เมื่อผู้ใช้เปิดเว็บไซต์ด้วย Browser เช่น Chrome สิ่งแรกตัว Browser จะไป Request ข้อมูลหาฝั่ง Server (ความจริงมันมีผ่านหลายชั้นทั้ง DNS server มากมาย แต่เอาคร่าว ๆ แบบนี้แล้วกัน)
- ฝั่ง Server ก็ทำการประมวลผลออกมาให้อยู่ในรูปแบบของ HTML, JavaScript และ CSS ทั่วไป (แน่นอนว่าเราอยากได้ข้อมูลจากฐานข้อมูลเค้าแต่ก็ทำไม่ได้น่ะ นอกจากจะสามารถมีสิทธิเข้าไปถึงเครื่อง Server ได้)
- Browser ได้รับไฟล์กลับมา และ แสดงผลให้กับผู้ใช้งาน
ในการทำ Web scrapping เราจะทำในขั้นตอนสุดท้ายนั่นก็คือขั้นตอนที่ 3 โดยเสมือนกับว่าเรานี่หล่ะจะเป็นคนเข้าใช้งานเว็บไซต์ทั่ว ๆ ไป แต่เราจะเขียนโปรแกรมให้มันสามารถดึงออกมาได้โดยไม่ต้องนั่งไล่หาเองด้วยมือ
เราจะใช้อะไร อ้างอิงว่าข้อมูลอยู่ตรงไหนในหน้าเว็บ?
ถ้าด้วยสายตาของเราก็ทำได้แน่นอน แต่การที่จะทำแบบนั้นในการเขียนโปรแกรมมันไม่ใช่เรื่องง่าย ๆ เลย ฮ่า ๆ ซึ่งอย่างที่บอกใบ้ไปครับว่าจริง ๆ แล้วหน้าตาเว็บไซต์ที่เราเห็นมันมี HTML เป็นเบื้องหลัง ดังนั้นเราจะทำหน้าที่ไต่ตาม Tag ของ HTML ครับผม
ใน Osmosis รองรับการอ้างอิง Tag ของ HTML อยู่ 2 แบบด้วยกันครับ
- CSS Selector — เราสามารถอ้างอิง Tag ต่าง ๆ ได้ด้วย CSS เช่น
เราก็เรียกใช้งานด้วย div#content
2. XPath — เราสามารถอ้างอิง Tag ต่าง ๆ ด้วยรูปแบบของ XPath ได้ด้วย เช่น
ข้อความที่อยากได้เราก็เรียกใช้งานด้วย A/B/C
เริ่มกันดีกว่า!
- ทำการ Clone code จาก repo ที่ผมสร้างไว้ดังนี้
git clone https://github.com/nitipatl/osmosis-playground
2. เมื่อเข้าไปให้ทำการติดตั้งให้เรียบร้อยด้วยคำสั่ง npm i หรือใครจะใช้ yarn ก็จัดเลยครับ
3. ทดลองสั่งการใช้งาน node-osmosis ที่ผมเขียนไว้เริ่มต้นด้วยคำสั่ง
node index.js
เราจะได้ข้อมูลออกมาหน้าตาแบบนี้ เป็นอันว่าสามารถทำงานได้ถูกต้อง

ทีนี้เราจะมาดูกันครับว่า Code ที่ผมเขียนเป็นตัวอย่างทำงานอย่างไรบ้าง ให้ลองดูที่ไฟล์ index.js ได้เลยครับ
- เรามาเริ่มต้นกันที่บรรทัดที่ 4 กันครับ มันคือคำสั่ง get ในการดึงข้อมูลเว็บไซต์ที่เราต้องการนำมาวิเคราะห์ โดยในครั้งนี้เราจะทดลองดึงข้อมูลจากเว็บไซต์ http://quotes.toscrape.com/ ที่มีคนใจดีสร้างขึ้นมาเพื่อให้เราได้ศึกษาการทำ Web scraping ครับ
- จากโค๊ดที่ผมเขียนไว้นี้ เราจะดึง tag title ออกมาจากหน้าเว็บไซต์ครับ ซึ่งก็จะเป็นคำสั่งในบรรทัดที่ 5
- ส่วนบรรทัดที่ 6 คือการระบุว่าก้อนข้อมูลที่ได้จาก title นี้ จะใช้ชื่อ attribute ว่า
titleกันครับ - ส่วนบรรทัดที่ 7 คือการที่หลังจากเสร็จแล้ว ให้เข้ามาแสดงข้อมูลที่เราได้ออกมาครับ
- ส่วนบรรทัดที่ 10–12 เป็นการแสดงช้อมูลต่าง ๆ อาทิ log, error log, debug log ครับ ตอนใช้งานจริงไม่ต้องใส่ก็ได้ครับ อันนี้ใส่ไว้ในขั้นตอนการพัฒนาจะช่วยให้ง่ายว่ามันติดปัญหาตรงไหนไหม?
ทีนี้ลองแก้บรรทัดที่ 6 เป็นแบบนี้ครับ
.set('test')
ผลที่ออกมาจะเป็นดังนี้ครับ

จะเห็นว่า Object ของข้อมูลที่ออกมาจะถูกเปลี่ยนเป็น attribute ว่า test แทนแล้วครับ
มาทำโจทย์กันครับ
โจทย์เพื่อทดลองใช้งาน node-osmosis ของเราคือเราจะดูดข้อมูลของเว็บนี้
Quotes to Scrape
"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking."quotes.toscrape.com
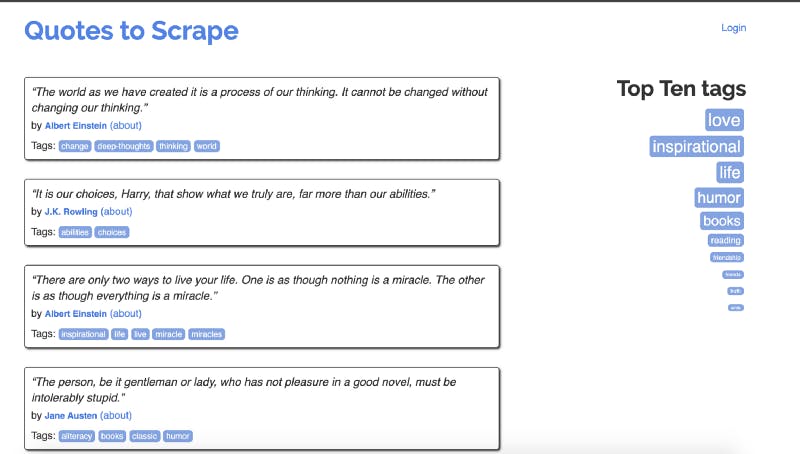
โดยเราจะดึงเอา quoute, tag, คนเขียน quote ที่มีอยู่หลายอันในส่วนซ้ายของเว็บออกมาจากเว็บนี้ครับ
ก่อนจะเริ่มกันเรามาแกะโครงสร้างของ HTML เว็บนี้เพื่อทำความเข้าใจกันก่อนน่ะครับ เพื่อจะได้นำเอาไปเขียนโปรแกรมดึงข้อมูลได้ในขั้นตอนต่อไป
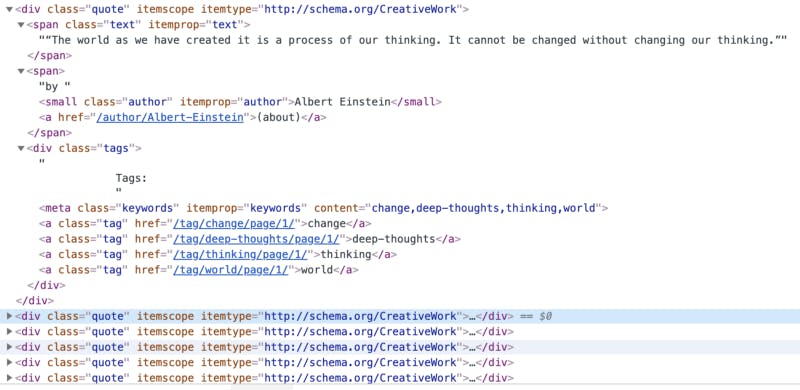
จากรูปด้านบนเราจะเห็นว่าแต่ละ quote จะแบ่งด้วย div class=”quote” ไว้ครับ และ ข้อความ quote จะอยู่ใน span class=”text” ครับ
- เราจะทำการทดลองดึงข้อมูลแต่ละ quote ออกมาก่อน
เมื่อดูสิ่งที่เราแก้ไขคือบรรทัดที่ 5 เราใช้การ find เพื่อค้นหา tag ของ div.quote (CSS Selector) ครับ จากนั้นบรรทัดที่ 6 คือการที่เราจะ set ค่าของการค้นหาลงใน attribute ครับ ซึ่งเราก็ใช้การเลือก span.text (CSS Selector เช่นกัน)
ผลลัพธ์ที่ออกมาเราจะได้ข้อมูลแบบนี้ครับ
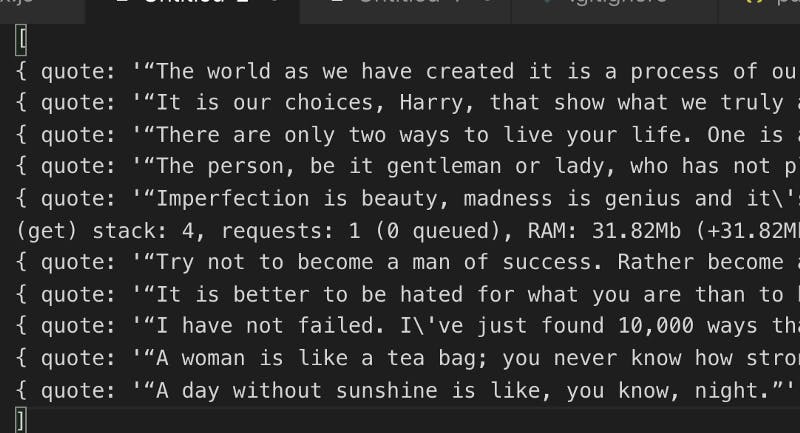
ซึ่งเป็น List Array ของ Object ที่มี attribute ว่า quote ครับ
2. ขั้นตอนถัดมาเราจะมาดึงข้อมูลชื่อของผู้เขียนกันครับ ย้อนกลับไปดูโครงสร้าง HTML ในหน้านั้น จะพบว่าข้อมูลของชื่อผู้เขียนอยู่ใน span > small > class ”author” ดังนั้นเราจะทดลองเขียนดังนี้ครับ
ลองดูบรรทัดที่ 8 น่ะครับ จะพบว่าเราเพิ่ม author ขึ้นมา โดยใช้ span > small.author ถ้าใครเคยเขียน CSS มาก็คงคุ้นน่ะครับ ถ้า งง ๆ ต้องลองศึกษาเรื่อง CSS เพิ่มเติมครับผม
ผลลัพธ์ที่เราได้ออกมาก็คือ…
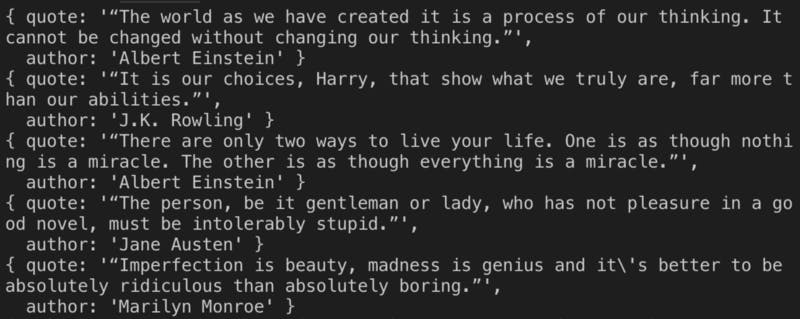
เราจะได้ author เพิ่มขึ้นมาแล้วในแต่ละ Object ครับ
โจทย์ที่อยากให้ทดลองทำกันเอง

ตอนนี้เราจะเห็นว่ามันมี Tag แสดงอยู่ในแต่ละ quote ครับ โจทย์คือเราจะดึงข้อมูลพวกนี้มาด้วยอย่างไร ทดลองทำเลยครับผมจะได้ทำความเข้าใจมากยิ่งขึ้น :)
ใบ้ให้ว่า… รอบนี้ข้อมูลที่เราอยากได้ต้องออกมาเป็น Array น่ะครับ ข้อมูลจะหน้าตาประมาณนี้ครับ

ลองดูตัวอย่างจากที่นี่ครับ
rchipka/node-osmosis
Web scraper for NodeJS. Contribute to rchipka/node-osmosis development by creating an account on GitHub.github.com
.
.
.
หากใครยัง งง ๆ สามารถดูเฉลยในโจทย์นี้กันได้ที่นี่เลยครับ
สำหรับบทความนี้ก็จบกันแต่เพียงเท่านี้ครับ ยังไงก็นำเอาความรู้นี้ไปใช้ในเชิงสร้างสรรค์กันน่ะครับผม :)